Apache+Python 實作中文斷詞系統
前言
課程作業需求,要將報導中文斷詞,並提取出名詞且計數,但上課教的方法太繁瑣複雜了。
手上的計畫案有用到 Jeiba 斷詞,於是我花三個小時架了一個中文斷詞系統供室友們使用。
實作過程
前端 HTML
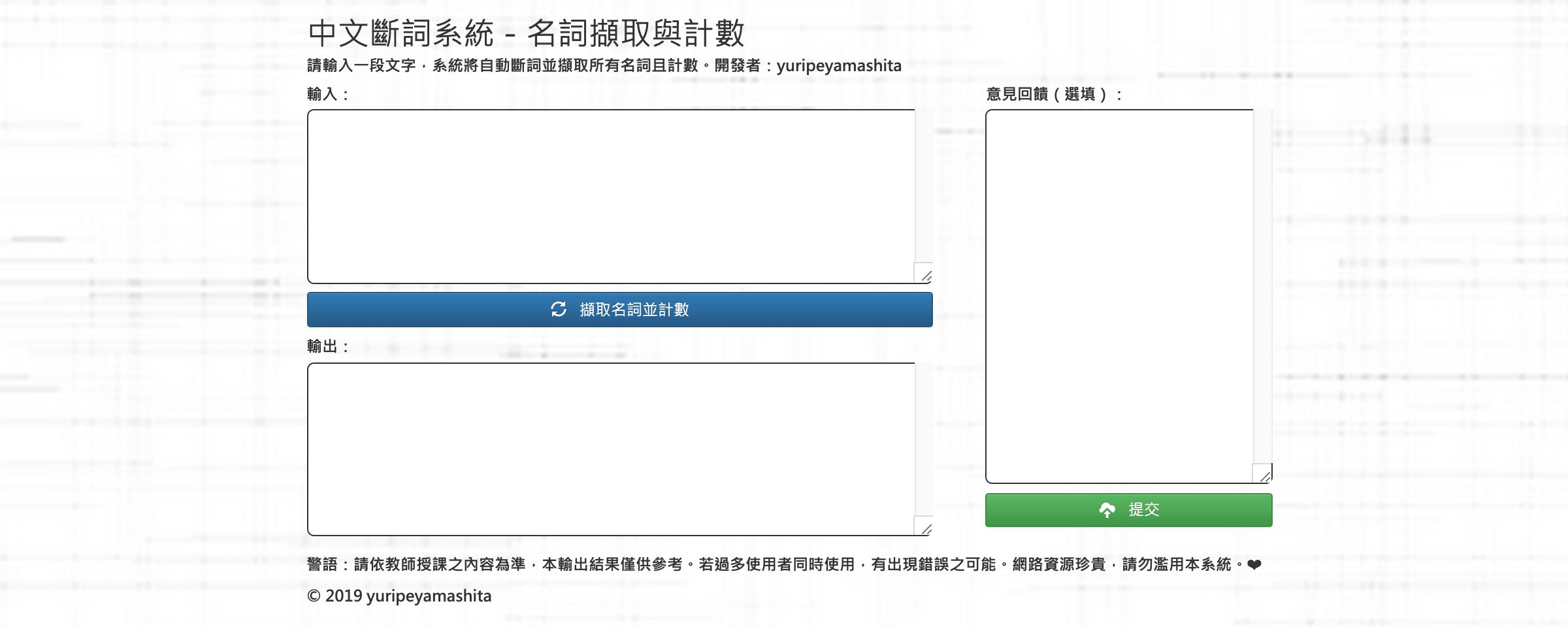
指定文字編碼為 UTF-8,並導入 jQuery,建立兩個textarea與一個button。
<head>
<meta charset="utf-8">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<label>輸入:</label>
<textarea id="input_txt"></textarea>
<button id="btn_cut">擷取名詞並計數</button>
<label>輸出:</label>
<textarea id="output_txt"></textarea>
</body>
前端 JS
這邊比較值得一提的,是我添加了一個下載 CSV 檔的功能,我嘗試過僅用註解那行的方式實現。
Chrome 於 macOS 上會自動添加副檔名.csv,但是於 Windows 不會,這不符合我的期待。
於是採用動態創建一個超連結元素,再為其添加屬性,最後模擬按下,來達成自帶副檔名的下載。
最後別忘了,要使 Excel 正常開啟 UTF-8 編碼的 CSV 檔,要加上 BOM(%EF%BB%BF)唷。
<script>
$("#btn_cut").on("click",function(){
$.ajax({
url: "./cut.py",
type: "post",
datatype:"json",
data: {'input_txt': $("#input_txt").val()},
success: function(response){
$("#output_txt").val(response.Ns_with_num);
// window.location.href = "data:text/csv;charset=utf-8,%EF%BB%BF"+response.Ns_with_num
var link = window.document.createElement("a");
link.setAttribute("href", "data:text/csv;charset=utf-8,%EF%BB%BF" + encodeURI(response.Ns_with_num));
link.setAttribute("download", "斷詞結果.csv");
link.click();
}
});
}
);
</script>
後端 Python
先指定 Python 路徑及導入必要的函式庫,透過 CGI 接收前端資料。
將回覆內容放進字典轉成 JSON,並直接print給前端。
#!C:/Python37/python
import json, cgi
import jieba.posseg as pseg
fs = cgi.FieldStorage()
input_txt = fs.getvalue("input_txt")
response = {}
result["Ns_with_num"] = cut_n(input_txt)
print("Content-Type: application/json\n\n")
print(json.dumps(response))
接下來寫功能函式cut_n(),第一步,先挑選出標籤是名詞的斷詞逐行放進字串Ns裡。
第二步,將Ns逐行取出並計算該行的詞語總共出現幾次,並在該行尾加上,次數。
因為每個詞語只需要出現一次詞語,次數就好,第三步,刪除全部的重複行。
def cut_n(source):
words = pseg.cut(source)
Ns = ""
for word in words:
if word.flag in ["n", "N"]:
if Ns == "":
Ns = word.word
else:
Ns = Ns + "\n" + word.word
Ns_with_num = ""
for line in Ns.splitlines():
count = Ns.count(line)
Ns_with_num = Ns_with_num + line + "," + str(count) + "\n"
for line in Ns_with_num.splitlines():
Ns_with_num = Ns_with_num.replace(line+"\n", "",Ns_with_num.count(line)-1)
return Ns_with_num
貼文底端