初探 Tensorflow 機器學習

前言
手上有個未來將利用 Tensorflow 做語音辨識的案子,趁著暑假的空檔研究並整理了思維。
也著手做了影像辨識的範例,辨識學校學生入口的四位數驗證碼。
本文所使用的 Tensorflow 版本為 1.13,已獲 2.0 版本更新的小節可參考連結。
關於 Tensorflow
TensorFlow 是一個開源軟體庫,用於各種感知和語言理解任務的機器學習。
被用於研究和生產許多 Google 商業產品,如語音辨識、Gmail、Google 相簿和搜尋。
最初由 Google 大腦團隊開發,用於 Google 的研究和生產,於 2015 年 11 月開源發布。
TensorFlow 提供了 Python,以及 C++、Java 等 API,底層核心引擎由 C++ 實現。
目前只有 Python API 較為豐富的實現了反向傳播部分。
所以大多數人使用 Python 進行模型訓練,但是可以選擇使用其它語言進行線上推理。
關於 機器學習
單眼的人臉辨識、Siri 的語音辨識看似神奇,但是電腦其實不是真的「看」得懂或「聽」得懂。
電腦只是將輸入(數字、影像、聲音)一律轉化為數字陣列,並套用公式計算。
例如:一張數字 7 的圖片,對電腦而言是一堆數字組合的陣列。
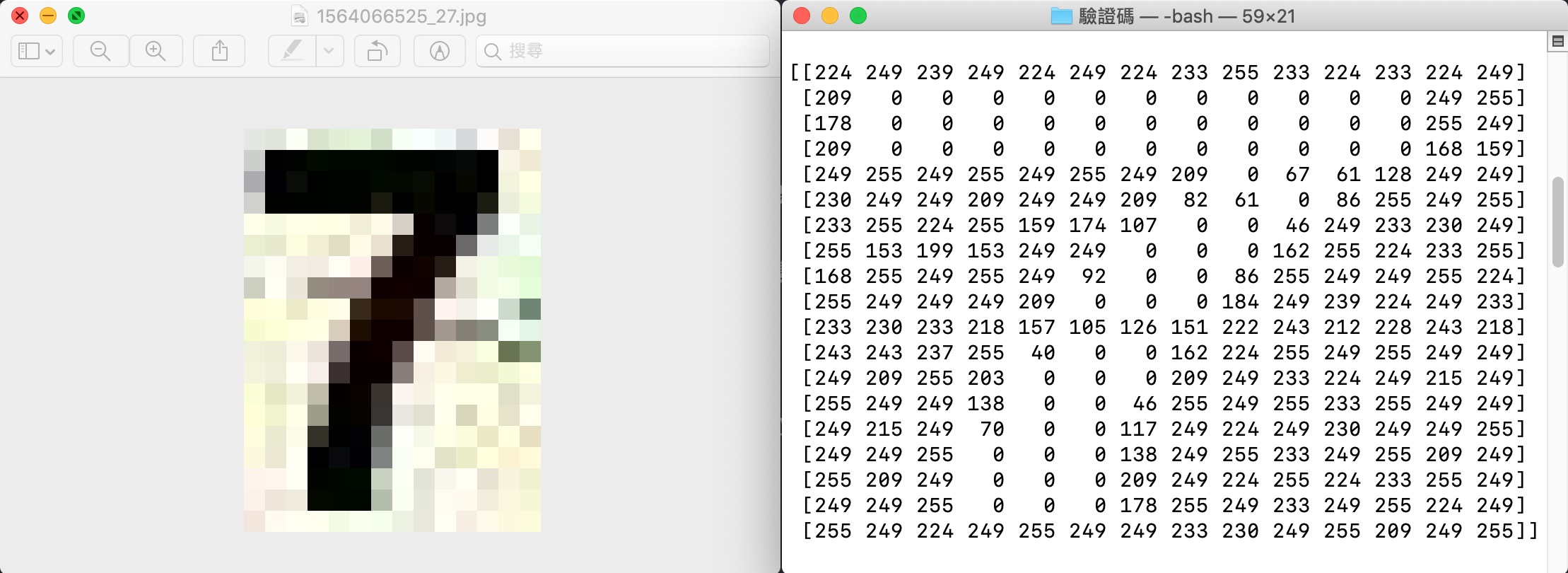
簡單來說,電腦其實就是在「算數學」而已。
至於,公式是什麼?電腦又計算了些什麼?這些本文不深究,我們只要學會如何使用 API 就好了。
影像辨識-訓練
事前準備
用 pip 即可安裝 TensorFlow 以及其他所需的軟體包:
pip install tensorflow
pip install opencv-python
pip install numpy
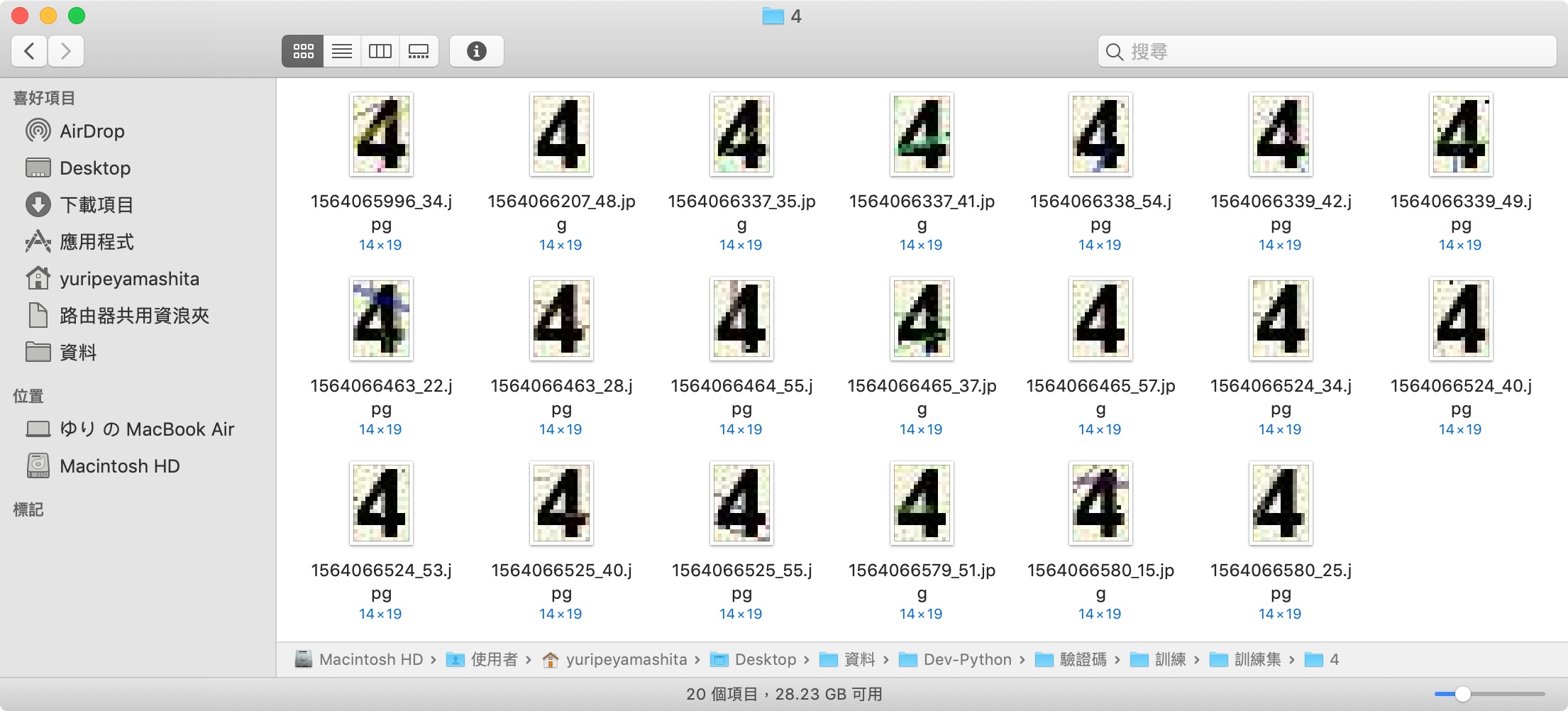
進行訓練前需要準備大量的樣本,我將驗證碼的每個數字擷取下來並放入對應名稱的目錄:
影像陣列化
這次簡單地使用只有一個隱藏層的 NN 標準神經網路,影像須先處理過,處理流程如下:
- 彩色影像轉成黑白。
- 黑白影像轉成二維陣列。
- 二維陣列扁平化。
原本彩色影像會有 RGB 三個通道,直接轉換會有三個二維陣列,為了降低複雜度,先將影像轉成黑白。
黑白影像轉成陣列就只剩一個二維陣列了,為了更精簡,我又將二維陣列再轉成一維陣列。
也就是說,一張樣本轉換為一條一維陣列,如果載入 50 個樣本的話就是 50 條。
再將這 50 條裝入一個陣列中,最終變成這種形態:[[1],[2],...,[49],[50]]。
但是,電腦根本不知道這 50 條分別代表什麼數字,所以需要再將每條貼上標籤。
標籤就用一條一維陣列裝就可以了:[0,0,0,0,0,1,1,1,1,1,...,9,9,9,9,9]。
def read_pic():
digits = []
labels = []
for folder in range(2,10):
for img in os.listdir("訓練集/{}/".format(folder)):
# 影像轉成黑白(.convert("L")保留灰階;.convert("1")非黑即白)
img_read = Image.open("訓練集/{}/{}".format(folder,img)).convert("L")
# 影像轉成二維陣列並扁平化
img_read = np.array(img_read, dtype=np.int32).flatten()
# 將每條裝入陣列 digits
digits.append([pixel for pixel in iter(img_read)])
# 貼上標籤
labels.append(folder)
return np.array(digits), np.array(labels)
影像陣列標準化
影像陣列中的每個數字,從 0 到 255 都有可能是,由於使用 NN 標準神經網路,範圍太大難以收斂。
於是要先將影像陣列標準化,讓範圍縮小但又不喪失特徵,我使用 Z-score 方法。
Z-score 標準化後是浮點數,但影像已轉成黑白,數值差距明顯,所以我再次轉成整數,加快收斂速度。
順帶一提,只有影像陣列需要標準化,標籤陣列不需要。
def z_score(np_array):
data = []
for row in np_array:
mean = np.mean(row, axis=0)
std = np.std(row, axis=0)
row = row - mean
row = row / std
row = np.nan_to_num(row) # NaN 置 0
data.append(row)
return np.array(data, dtype=np.int32) # 再次轉成整數
建構神經網路
直接使用 TensorFlow 提供的 API 建構就可以了,很方便。
首先,保留兩個輸入的位置 x, y,分別是影像陣列與標籤陣列。
再來建立神經網路層,一個隱藏層(10 個神經元、激勵函數 relu)。
一個輸出層(10 個神經元),數字要分類 0-9,共 10 個類別,所以神經元必須為 10。
接著建立最佳化器(optimizer)去降低誤差,學習效率為 0.05。
最後建立會話,會話指向初始化所有變數。
tf_x = tf.placeholder(tf.float32, x.shape) # 輸入 x
tf_y = tf.placeholder(tf.int32, y.shape) # 輸入 y
l1 = tf.layers.dense(tf_x, 10, tf.nn.relu) # 隱藏層
output = tf.layers.dense(l1, 10) # 輸出層
loss = tf.losses.sparse_softmax_cross_entropy(labels=tf_y, logits=output) # 計算誤差
accuracy = tf.metrics.accuracy(labels=tf.squeeze(tf_y), predictions=tf.argmax(output, axis=1),)[1] # 計算準確性
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.05) # 最佳化器
train_op = optimizer.minimize(loss) # 降低誤差
sess = tf.Session() # 建立會話
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op) # 初始化所有變數
訓練並儲存結果
將影像陣列與標籤陣列傳值進會話,訓練 5000 步,每 5 步輸出準確性。
最後儲存訓練後的參數結果。
import os
import tensorflow as tf
import numpy as np
from PIL import Image
x, y = read_pic()
x = z_score(x)
for step in range(5000):
_, acc, pred = sess.run([train_op, accuracy, output], {tf_x: x, tf_y: y})
if step % 5 == 0:
print('Accuracy=%.2f' % acc)
saver = tf.train.Saver()
saver.save(sess, './params', write_meta_graph=False)
print("Saved.")
影像辨識-推理
影像陣列化
與訓練時大同小異,訓練時如何處理,推理時就要比照辦理。
下載驗證碼,轉黑白,轉陣列,分割,扁平化。
url = "https://eap10.nuu.edu.tw/CommonPages/Captcha.aspx"
def load_pic():
# 下載驗證碼
res = requests.get(url)
# 讀取驗證碼並轉為陣列
#.convert("L")保留灰階;.convert("1")非黑即白
pil_image = Image.open(BytesIO(res.content)).convert("L")
np_image = np.array(pil_image, dtype=np.int32)
# 儲存驗證碼
pil_image.save("tmp.jpg")
# 將陣列分割成四個數字並攤平成一維
cut_area = [(7, 7, 14, 19), (21, 7, 14, 19), (34, 7, 14, 19), (48, 7, 14, 19)]
digits = []
for x,y,w,h in cut_area:
img_read = np_image[y:y+h, x:x+w]
digits.append([pixel for pixel in iter(img_read.flatten())])
return np.array(digits)
影像陣列標準化
同訓練。
def z_score(np_array):
data = []
for row in np_array:
mean = np.mean(row, axis=0)
std = np.std(row, axis=0)
row = row - mean
row = row / std
row = np.nan_to_num(row) # NaN 置 0
data.append(row)
return np.array(data, dtype=np.int32) # 再次轉成整數
建構神經網路
訓練儲存的只有參數結果不是模型,所以神經網路需重建。
用於推理就無法輸入標籤陣列了,因為目標即是推理出標籤。
tf_x = tf.placeholder(tf.float32, x.shape, name="tf_x") # 輸入 x
l1 = tf.layers.dense(tf_x, 10, tf.nn.relu) # 隱藏層
output = tf.layers.dense(l1, 10) # 輸出層
sess = tf.Session() # 建立會話
saver = tf.train.Saver()
saver.restore(sess, "./params") # 讀取載入參數
推理並輸出預測值
輸出的預測值是四個一維陣列,每個陣列有 10 個元素,分別代表 0-9 的相似度。
例如:
[0.1, 0.6, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]即代表數字 1。
[0.1, 0.3, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.8]即代表數字 9。
故用argmax(1)取最大值的索引即可。
import os, requests
import tensorflow as tf
import numpy as np
from PIL import Image
from io import BytesIO
x = load_pic()
x = z_score(x)
pred = sess.run([output], {tf_x: x})
print("=====")
print(pred[0].argmax(1))
print("=====")